About the author
Will Barrett is a Software Engineer, Technical Lead, and Engineering Manager from the San Francisco Bay Area with over 14 years of experience. He’s a Superset PMC Member of The Apache Software Foundation. He’s held staff software engineer and senior engineer roles at Change.org, Entelo, Sqwiggle and Preset.
Will is the author of On Learning to Program, a blog for new Software Engineers entering the industry. Will is also a certified reviewer on PullRequest where he’s caught hundreds of bugs and other critical issues for over 30 teams.

What is Apache Spark?
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
- Apache Spark project documentation
Apache Spark started as a research project at the UC Berkeley AMPLab in 2009, and was open sourced in early 2010. Many of the ideas behind the system were presented in various research papers over the years. After being released, Spark grew into a broad developer community, and moved to the Apache Software Foundation in 2013. Today, the project is developed collaboratively by a community of hundreds of developers from hundreds of organizations."
- Apache Spark project website
At time of publication the Spark project has approximately 30,700 Stars on GitHub, over 24,500 forks, and over 31,000 commits on the main development branch. The overwhelming majority of Spark is written in Scala.

Apache Spark’s Contributor Guidelines
Spark has a substantial set of Contributor Guidelines on their project website. Interestingly, the first few sections of the Contributor Guidelines cover ways to contribute to the project that are not directly contributing core code - these include helping other users via mailing list or StackOverflow, testing releases, reviewing changes, contributing documentation, and filing bug reports.
Custom PR Management UI
Under the “Review Code” contribution method in the Contributor Guidelines, we come across our first interesting discovery - Spark has a custom UI for filtering PRs and showing their status:
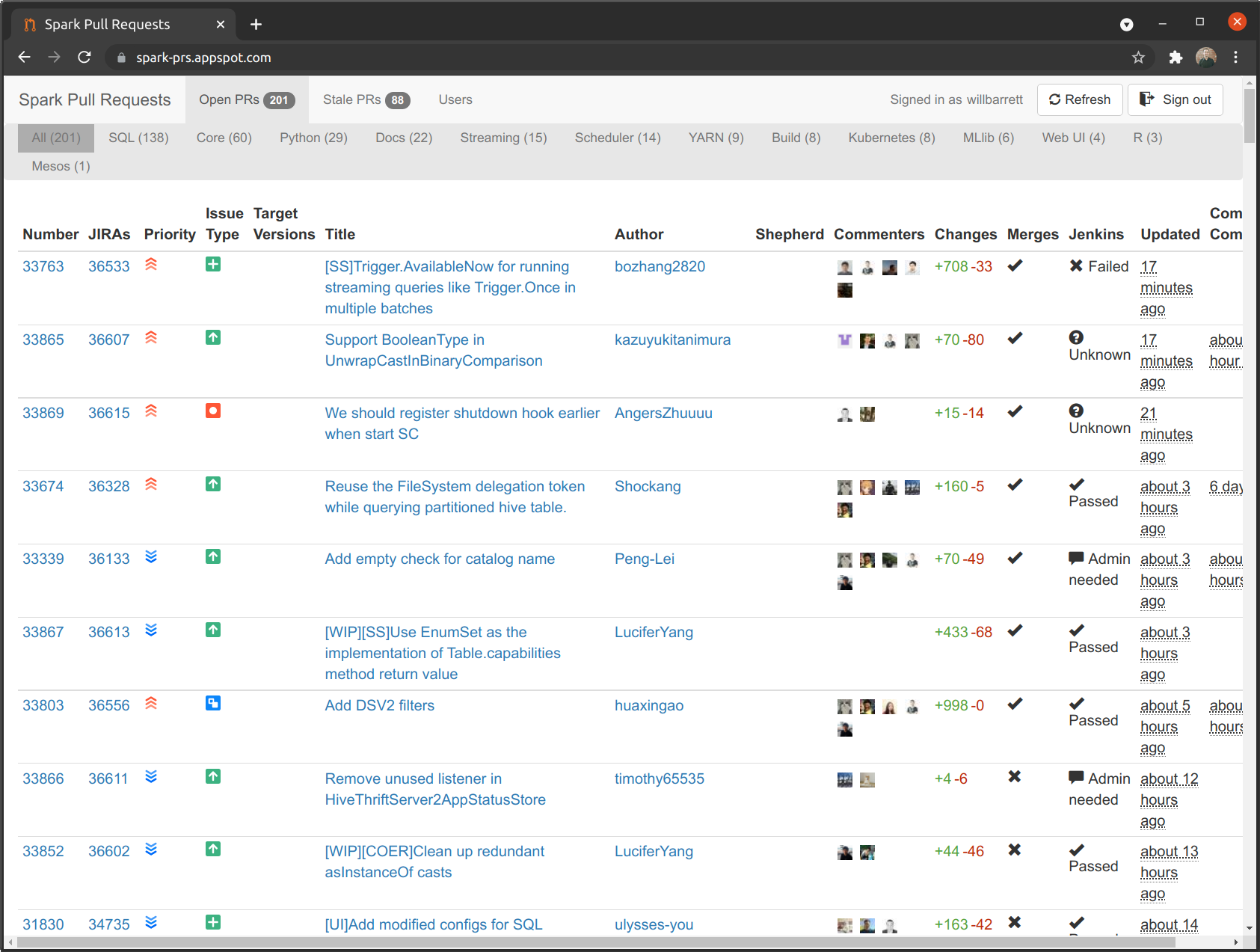
This UI allows the user to filter PRs by open and stale, the part of the project the PR is related to (Docs, Streaming, SQL, Web UI, etc.), and to sort by a number of meaningful attributes of the PR, such as JIRA issue number, author, last updated, size of the change set, Jenkins CI build status, and when it was last commented on by a committer to the project.
As a large project with a high velocity, this UI is a very helpful addition for maintainers - as someone who has worked on high-velocity systems before, PR management can become a nightmare, and being able to filter the PR list only to the subset of pull requests that I’m interested in would have been very helpful.
Pull Request Naming
Similar to what we saw previously when looking at Apache Superset, Spark has very strict naming rules for its pull requests. Incomplete pull requests must be prefixed with [WIP], each PR must be prefixed with a JIRA issue identifier to tie changes back to JIRA issues, such as [SPARK-36613], and all PRs must have a relevant description.
PR Labeler Bot
Looking at the Github Actions for the repository, we can see how this custom UI is partially driven by Github Labels:
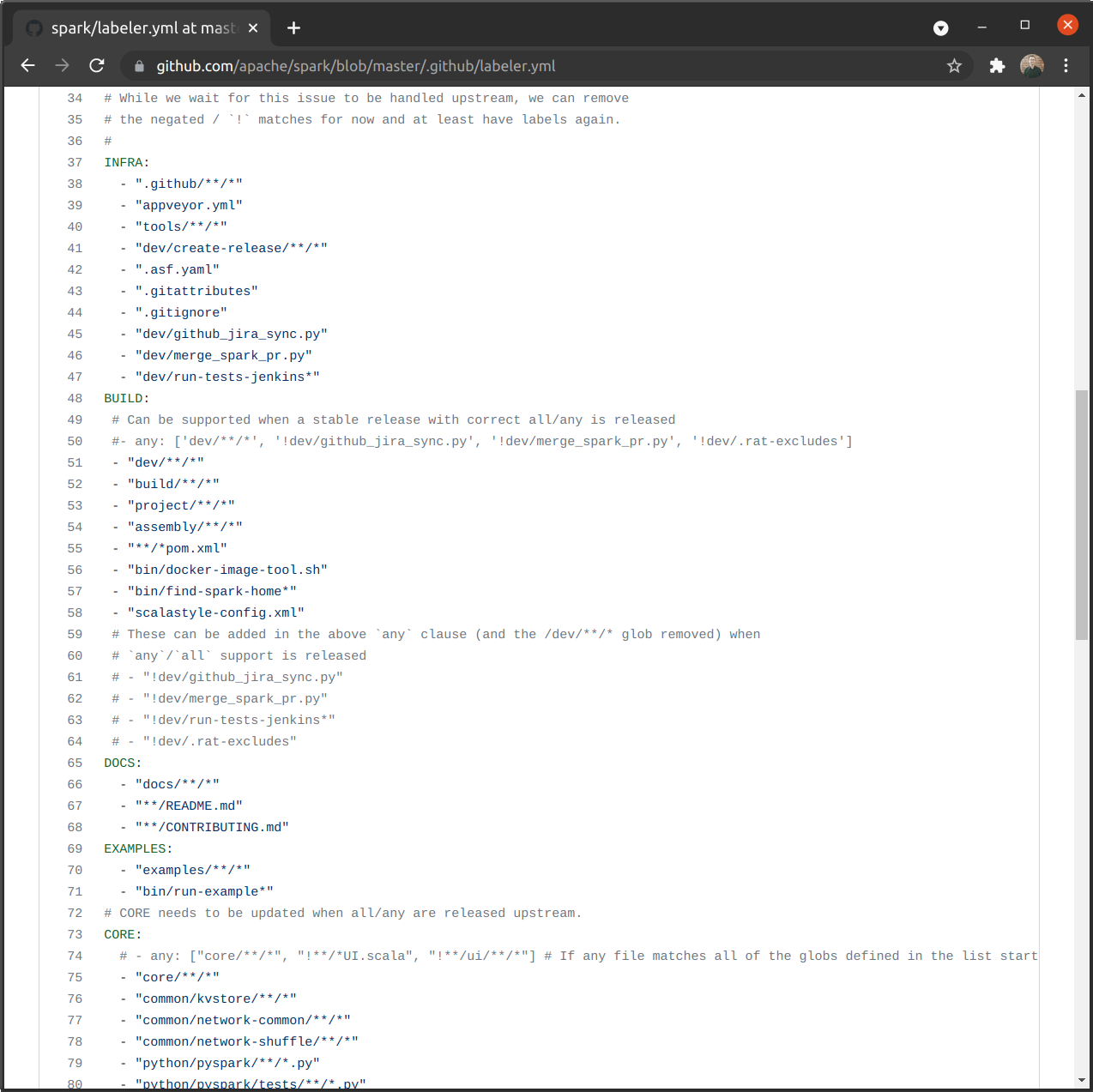
The labels are applied when the files matching the pattern in the YAML configuration are changed in a PR. This is an excellent way to automate the management of PR classification, removing the headache from project maintainers of manually tagging each and every PR with the relevant labels.
Pull Request Template Focused on Helping Reviewers
Spark’s Pull Request Template is very focused on helping out the reviewers. It’s rather lengthy, so I’ve refrained from reproducing it here. There are a few bits worth calling out:
### What changes were proposed in this pull request?
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
This section is focused on making sure code reviewers have all of the necessary context to understand the proposed change, and links to relevant documentation they may need to understand any related system. One of the false assumptions of Software Development for any project like Spark with a large number of external integrations is that the maintainers of the project are experts in those systems. Generally different integrations may be maintained by different committers, or committers may have a general, but not specific, understanding of how the integrations need to work. Requesting documentation links is a good way to ensure that the author passes on their understanding of those integrations to the reviewer when relevant.
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
Often code authors believe that the changeset under review contains all the context necessary to understand the motivation for the change. Isn’t it obvious that this is a bug? Isn’t the usecase clear simply from the code? The vast majority of the time, the code needs more explanation. Especially on large, fast-moving projects like Spark it’s unlikely that many of the reviewers have full context on the majority of the application. Adding good justification of the change for the reviewers can greatly speed up the process of code review.
### Does this PR introduce _any_ user-facing change?
<!--
Note that it means *any* user-facing change including all aspects such as the documentation fix.
If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible.
If possible, please also clarify if this is a user-facing change compared to the released Spark versions or within the unreleased branches such as master.
If no, write 'No'.
-->
Oh, release management. One large challenge for open source maintainers is updating documentation and providing good release notes when a new version is shipped. Asking PR authors to enumerate user-facing changes can greatly help the maintainers in generating these release notes and ensure that PRs are pulled into the right release number - projects following Semantic Versioning or similar will have rules on release numbering and if these descriptions are accurate they will allow contributors to make good decisions about which release a certain PR should fall into.
Code Review Criteria
Apache Spark has a section in its Contributor Guidelines covering Code Review Criteria that are likely to applied when reviewing code. The fact that these criteria are shared up-front with new contributors is a positive, and something I think more projects (both open- and closed-source) should consider imitating.
Some of the more interesting points in this are in the “Negatives, Risks” section which deals with code changes that are not likely to be accepted by the project. I found the following interesting:
“Introduces complex new functionality, especially an API that needs to be supported” and “Changes a public API or semantics (rarely allowed)” - it appears that the maintainers believe the Spark project to be functionally quite complete at this stage (and after 30,000+ commits, I think they have justification) and are optimizing for stability of the existing project. Given the pain involved in supporting the alteration of a public API in a core system, this is a worthy goal.
“Adds user-space functionality that does not need to be maintained in Spark, but could be hosted externally and indexed by spark-packages.org” - Spark has leveraged a packaging system to allow extensions to the Spark project that can be maintained by other groups, outside of the core Committers to the main Apache project. This is interesting because it allows Spark to be expanded without forcing more change into the core repository.
“Makes lots of modifications in one “big bang” change” - smaller changes are easier to review, and should they cause issues they are easier to revert. This is a common best-practice when engaging in Software Development, particularly when dealing with mature, complex systems.
One of the positives is also worthy of note - if a “Change has already been discussed and is known to committers” it is more likely to be merged. On larger projects with a management group, drive-by contributions can be more of a problem than they are worth. If someone reaches out to committers before proposing a change the committers have the opportunity to discuss the merits and pass on additional requirements to the new contributor before the work is done. This makes it more likely that the end result will be something positive, rather than negative for the community.
Find this useful? Be sure to check out What We Can Learn About Code Review From the Apache Superset Project.
