About the author
Will Barrett is a Software Engineer, Technical Lead, and Engineering Manager from the San Francisco Bay Area with over 14 years of experience. He’s a Superset PMC Member of The Apache Software Foundation. He’s held staff software engineer and senior engineer roles at Change.org, Entelo, Sqwiggle and Preset.
Will is the author of On Learning to Program, a blog for new Software Engineers entering the industry. Will is also a certified reviewer on PullRequest where he’s caught hundreds of bugs, security issues, and other critical issues for over 40 teams.

The Open Web Application Security Project (OWASP) has a thorough definition of the types of failures defined by “Cryptographic Failure”. The definition is quite extensive and thorough, so we’re going to be working from a shortened version.
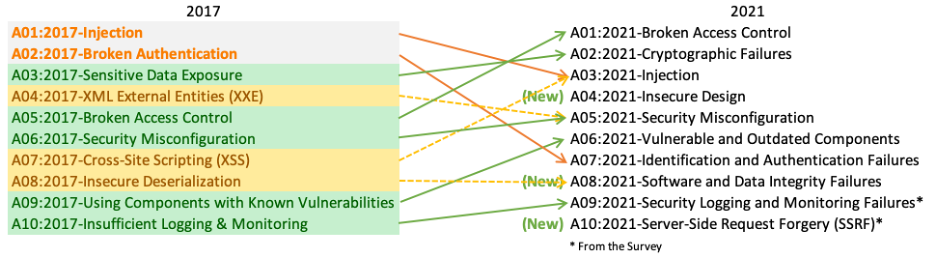
Working Definition of Cryptographic Failure
Sensitive data that should be protected is either not protected or protected by insufficient cryptography. Let’s look at this definition. There are 3 important terms here:
- Sensitive Data
- Not Protected
- Insufficient Cryptography
What is Sensitive Data?
Sensitive data is any information that an organization would not want to be visible by the general public. This includes information important for security of the platform (keys, passwords, usernames), private info about users of the service (email addresses, names, government ID numbers), and anything having to do with money changing hands (credit card numbers, bank account info, and the like).
Not all types of sensitive data are created equal. Some, like passwords, should be hashed in such a way that they are never recoverable to plain text. Others, like names and email addresses, can likely be handled as plain text most of the time but should be protected as an aggregate list. Unfortunately how sensitive each item is considered to be depends partly on legislation (such as the GDPR and CCPA laws), partially on industry standards (the PCI DSS for credit card information), and partially on an individual organization’s security posture and/or policy. When in doubt if a piece of information should be considered sensitive, generally it’s best to default to using the highest level of protection that will still allow use of the data to support the feature or tool you’re building.
What does it mean to not protect data?
Once a protection strategy is in place for a type of data - let’s use a bank account number as the example - straying from that strategy means the data isn’t protected. So, if we store bank account numbers encrypted at rest and transmit them over an encrypted connection doing anything else would count as not protecting them. Here are some common ways protected data can be mishandled and exposed:
- Allowing the data to be exported in plain text.
- Writing the data to a log file in plain text.
- Sending the data in plain text over an unencrypted connection (like FTP, HTTP, email, or TLS).
- Checking the data into source control.
- Writing secure data to a cache in plain text.
What does insufficient cryptography mean?
In short, insufficient cryptography is cryptography that can be easily compromised. It is cryptography that does not provide a sufficient level of security. The basic concept behind cryptography is not to create ciphers that are impossible to crack, but creating ciphers that are impossible to crack within a reasonable timeframe given the computational power currently available. In other words, it may not be impossible to crack from a conceptual standpoint, but it’d be excessively difficult and impractical to do so. So insufficient cryptography generally means cryptography that can be cracked in a reasonable amount of time with the hardware available to the attacker.
Cryptography is a deep topic and creating secure cryptographic functions can be extremely difficult. The first rule is: don’t ever roll your own cryptography. Anything that a programmer comes up with on their own, save experts in computer science who specialize in the research and design of cryptographic functions, is going to be fundamentally flawed in a way that makes it easy to crack. So, it’s best to assume that any home-grown cryptography is weak and should be replaced.
Even when using cryptographic functions created by experts, it’s still possible for the cryptography to be insecure. Certain functions, such as MD5, SHA1, and PKCS number 1 v1.5, either have insufficient entropy - meaning a modern computer can easily crack them in a reasonable amount of time - or have known exploits that make them insufficient for encryption today. Over time, as computers become faster and more efficient, the list of secure cryptographic functions changes. For example, DES (Data Encryption Standard) used to be considered secure, but its key length of 56 bits makes it now easily broken with modern computers (and the NIST withdrew it as a Federal Information Processing Standard in 2005). The AES (Advanced Encryption Standard) family of functions with longer key lengths is still considered secure, but that may change with future advances in hardware - quantum computing in particular threatens to make many current encryption standards obsolete. All of this is to say, it is necessary to stay up to date on which algorithms are still considered secure.
Finally, once a secure algorithm (such as AES256) has been chosen, it is important to use the algorithm correctly and maintain security over time. This means avoiding problems like reused salts, easily-guessed encryption keys and initialization vectors, and providing ways to rotate the encryption keys periodically. Let’s look at why each of these is important:
Reusing Salts
When hashing information, such as a password, reusing salts can greatly reduce the amount of time it takes to crack encryption as there is a part of the encrypted string that is predictable - this allows the attacker to attack multiple encrypted strings with the same “guess”, resulting in a lower time to crack the encryption overall.
Easily-Guessed Encryption Keys
An easily-guessed encryption key is far worse than an easily guessed password. Should an attacker gain access to the encrypted data, they can perform a dictionary attack on the data, where they try decrypting the information with a wide variety of common terms to see what results in usable data. This type of attack can be performed much faster than a brute-force attack with random strings.
Bad Example:
ENCRYPTION_KEY='SUPERSECRET'
Good Example:
ENCRYPTION_KEY='HTjDYbPJcAb94qSTRTRnnS87tTYYSCZfK2rzs7hGSEP4dDuMY4XvVHNa'
Key Rotation
Encryption keys can become compromised accidentally quite easily. All it takes is an errant commit on a repository and the encryption key can be shared in a permanent way in plain text. Additionally, employees with access to encryption keys can leave the organization from time to time. Whenever an encryption key is known to someone who should not have access to it or could be reasonably assumed to be known it will become a requirement to rotate the key. This means updating to a new encryption key and re-encrypting all of the encrypted content that key protects.
If that sounds potentially dangerous, it’s because it can be. The process should be fully automated, and it is a best practice to take a backup of the encrypted data before rotation, perform the rotation, then delete the backup. Remember that old backups may exist that still leverage the old encryption key. These backups should either be re-encrypted as well or purged to avoid potential data compromise.
Conclusion
This is not a complete exploration of all the ways cryptography can fail, but it should shed some light on the common concerns web application developers will face as they work towards securing their applications. Cryptography is a deep topic and the best advice is to delegate cryptographic security to known and trusted libraries developed by experts while keeping an inventory of stored data and understanding what level of security is required for each type in your organization. This will give most programmers the best likelihood of avoiding cryptographic failures and ensuring the programs they build are secure.
Find this useful? Be sure to check out these additional articles by Will Barrett:
- What We Can Learn from the Ruby on Rails Project about Code Review
- 5 Ways I Provide Value as a PullRequest Reviewer When I Start Reviewing a New Project
- How to Catch the Top OWASP 2021 Security Category - Broken Access Control - in Code Review Part 1 and Part 2
- Tips for Migrating to a New Computer for Programmers
- The Top 5 Most Common Security Issues I Discover When Reviewing Code
- Reviewing One’s Own Code
- Handling Code Reviews with Empathy
- What We Can Learn About Code Review From the Apache Superset Project
- What We Can Learn About Code Review From the Apache Spark Project
