See how your team compares to similar companies
We are excited to announce a new feature we’ve been rolling out to select PullRequest customers: Benchmarks. We have been developing and using these key metrics, based on anonymized datasets from hundreds of development teams internally for several months in order to aid our network of expert engineers in providing PullRequest customers with feedback of maximum utility and value. We’re excited to begin offering this information to our customers so teams can have visibility into how they stack up to companies of similar size and composition, identify issues, and set high-level goals.
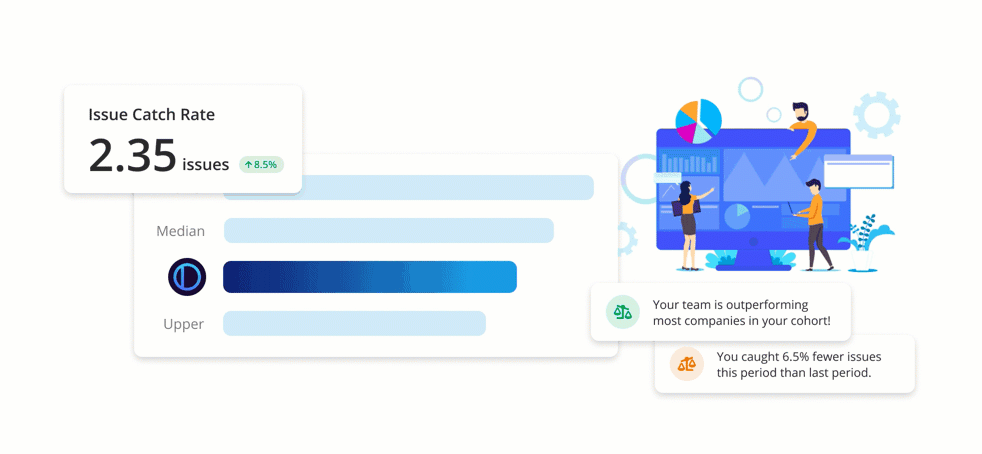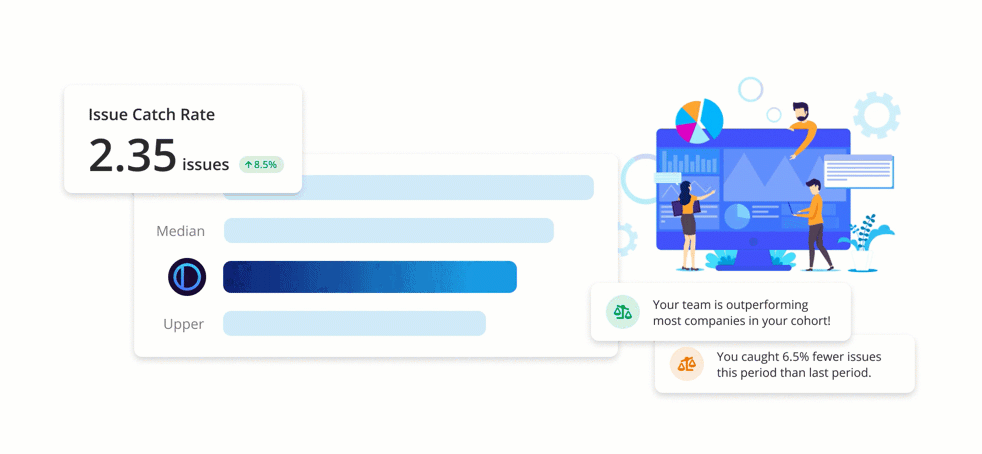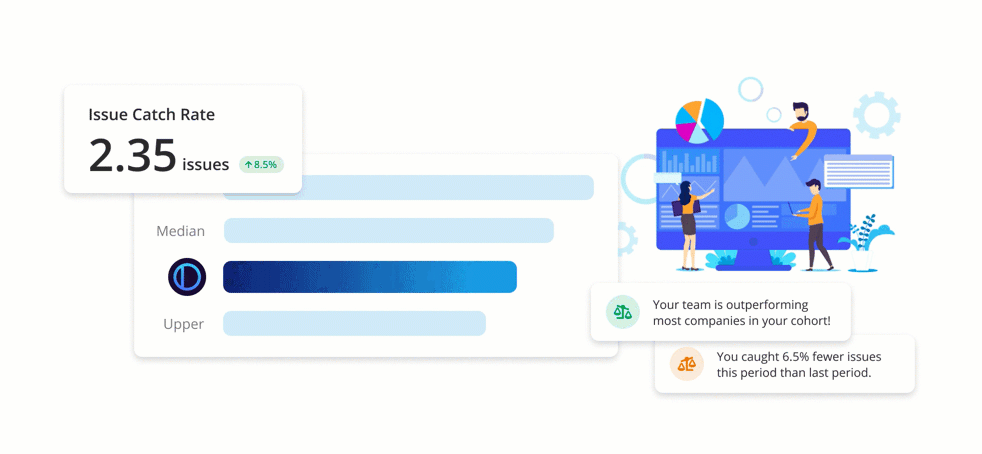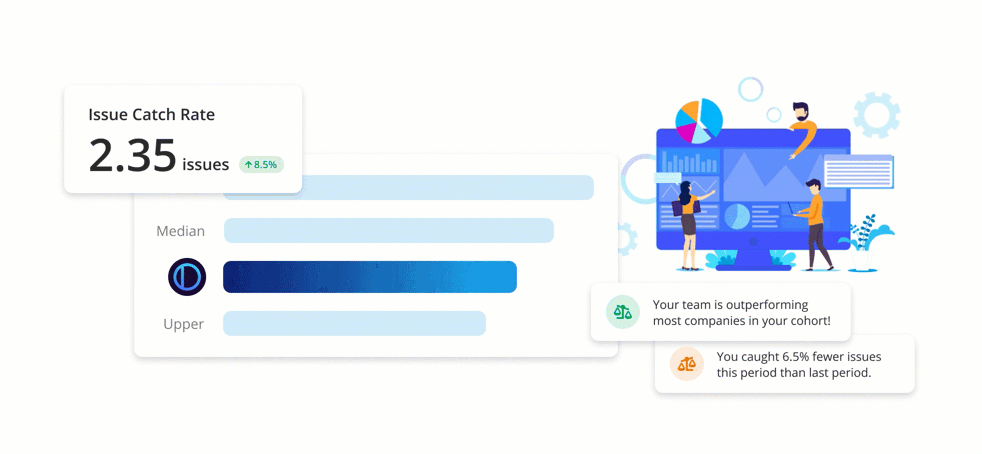
Benchmarks are an easy-to-understand set of metrics, giving development teams unique insight into the health and state of their code review process. Teams using PullRequest are able to track their scores over time and where they stand compared to similar companies.
The Benchmark scores were carefully designed and normalized such that scores are consistently relevant regardless of things like fluctuations in the volume of code committed and changes in team size or composition. Benchmark reporting also includes 30-day comparisons making it easy to track code review process improvements over time.
Issue Catch Rate
One of the key Benchmark metrics PullRequest detects and tracks for customers is “Issue Catch Rate”. An “issue” is identified when an inline comment left by a reviewer of the pull request that either resulted in a change to the pull request or has been deemed likely to have provided useful insight to the code author.
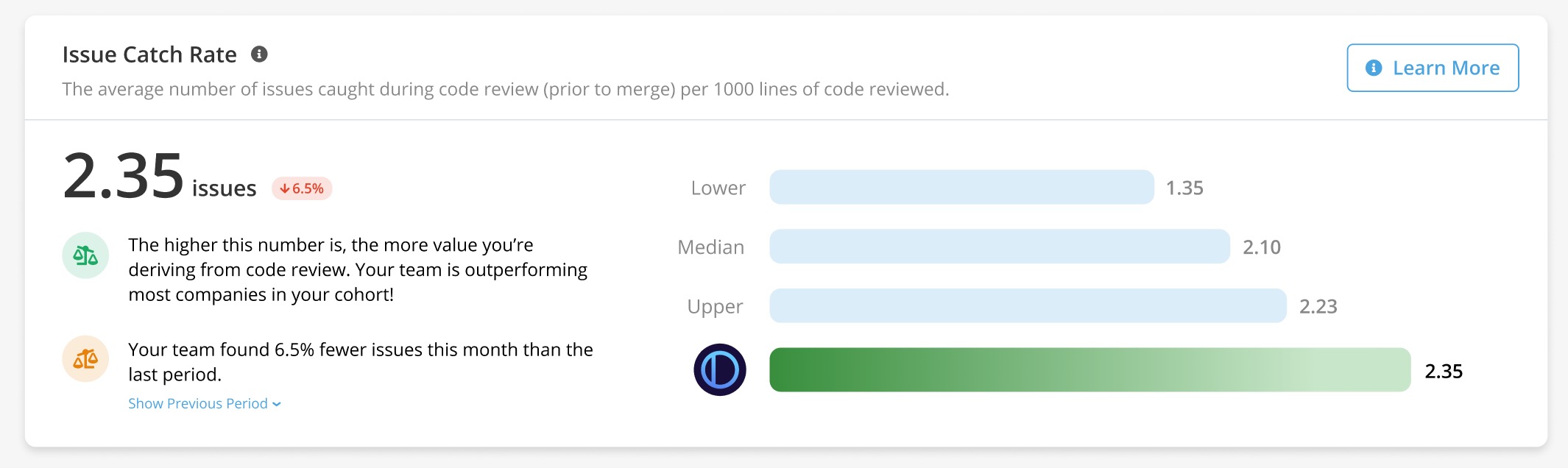
Perhaps contrary to what the verbiage implies, an increase in the number of issues caught is generally desired as opposed to a decrease. When a greater number of issues are cited and addressed on the code review level, they’re not manifested later as costly bugs, security vulnerabilities, performance issues, or components that are time-consuming to maintain. In other words, a high number of issues caught during code review is indicative of a healthy and effective code review process.
The metric captures one of the many core benefits of code review: improving the quality of the author’s code. If a team approves every pull request with shallow or blind approval (“lgtm”), it would result in a score of 0. However, if changes to a project’s code are thoughtfully assessed and reviewer feedback is well-received by the author, this score will reflect that positive feedback loop.
Background & methodology 🔬
The PullRequest team has invested a great deal of time and research finely tuning this metric as it is susceptible to noise. Anonymized datasets from hundreds of teams, thousands of pull requests, and millions of lines of code were assessed as part of these efforts. Code review processes are inherently human, and no 2 development teams are the same.
The calculations exclude things like automated messages from bots, as well as replies to existing comments or comments left by the author themselves. The data for this statistic is also normalized to a count of issues caught per 1,000 lines of meaningful change that are part of merged pull requests. PullRequest filters out activity and events that are likely to pollute the data, such as generated files and other types of files that are not usually reviewed, in order to provide an accurate figure.
Improving your score 📈
Our research has shown a very strong and consistent correlation between issues caught during code review and teams that receive code review from highly experienced reviewers. This holds true even when the authors of pull requests are exceptional software engineers themselves (and great reviewers for their teammates); a good reviewer will consistently identify meaningful improvements or useful discussions to have. This isn’t exclusively an inherent quality of an individual reviewer but is often a product of the culture and emphasis put on encouraging code review. Many teams will unintentionally discourage code review by emphasizing other aspects of the development process with greater weight. In many cases, this is an antipattern that rewards teammates who write more code and open more pull requests while inadvertently discouraging code review activities.
Further, the size of changes introduced per pull request has a significant impact on the number of issues caught. This is commonly due to bikeshedding, a pitfall observed in code review where the larger and more complicated a code review is, the less attention will be given to the important details. This results in a suboptimal code review process; issues that would otherwise be caught in code review are experienced by end-users instead.
See your team’s score in minutes
Connect your team’s GitHub, Bitbucket, GitLab or Azure DevOps repositories to PullRequest to see how you compare to other similar companies. We’ll notify you when the your scores are ready.
Access to PullRequest’s Code Review Benchmarks is free along with other great tools like PullRequest’s Repository Insights Dashboard.
Learn more about Benchmarks
Learn about the other code review metrics PullRequest tracks, our methods for deriving and comparing data, and how to improve your score in our Benchmarks Documentation.
Have questions?
We’d be happy to answer them, and we’d love to know what you think. Email benchmarks@pullrequest.com.
Or, schedule a 15 minute meeting with a member of our team.
